
Data Connectors: Automate Data Ingestion
Arkham's Data Connectors provide a library of pre-built, production-grade integrations to automate loading data from source systems directly into the Arkham Lakehouse. Our service is designed to eliminate the need for custom environments with custom ingestion scripts, enabling you to build reliable data pipelines in minutes, not months.
.jpg)
How It Works: From Source to Lakehouse
Our Data Connectors streamline the entire ingestion process through a low-code UI, abstracting away the complexity of managing individual data pipelines. This architecture ensures that data lands in the Bronze layer of your Lakehouse reliably and on schedule.
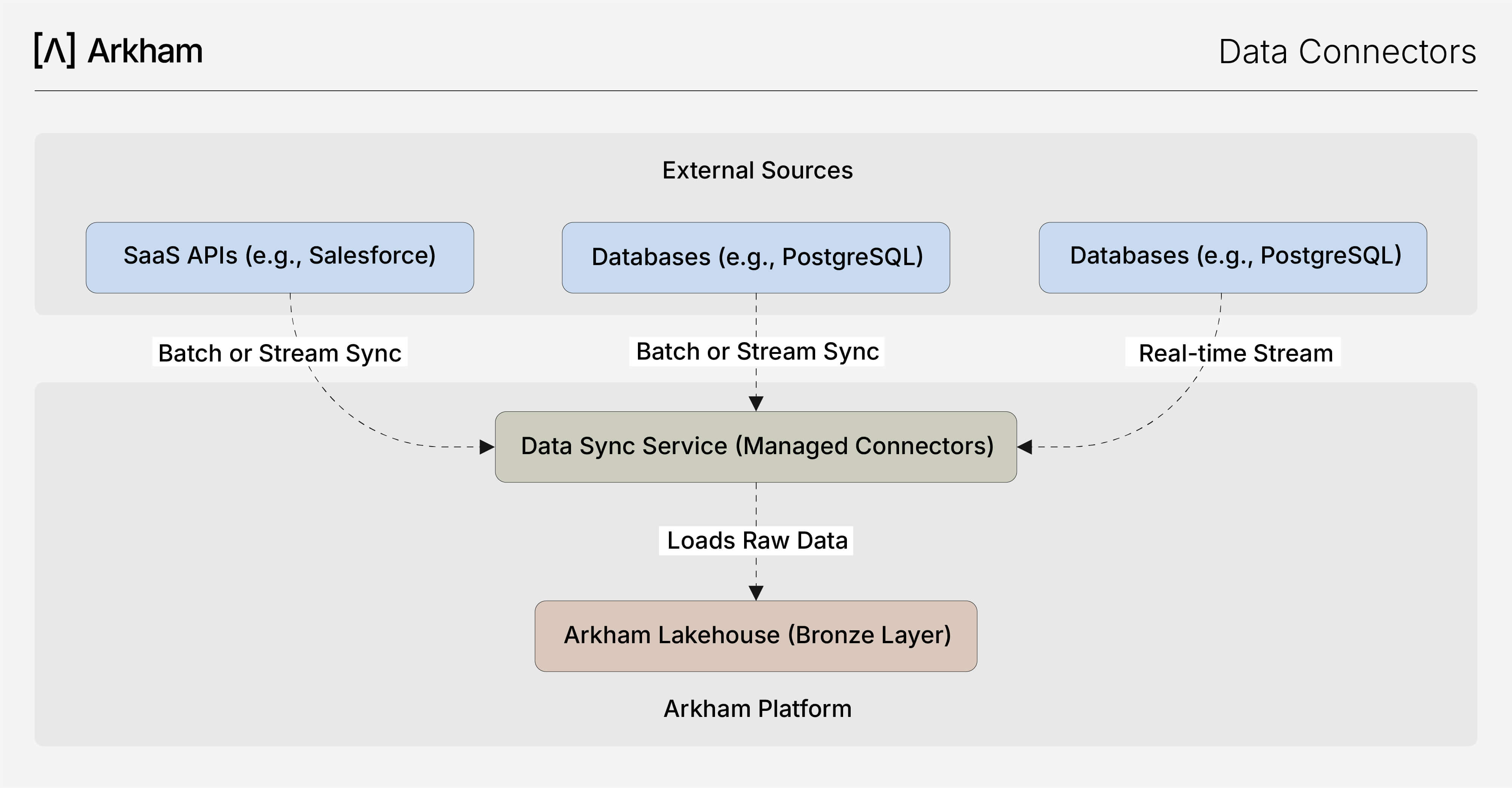
The process is straightforward:
- Select a Connector: Choose from a wide range of sources.
- Configure Credentials: Securely provide access credentials through our integrated vault.
- Define Sync Behavior: Select the tables, topics, or objects to sync and define the schedule (e.g., batch, incremental, or streaming).
- Monitor & Manage: Track sync jobs, view logs, and manage connections from a centralized control panel.
Key Technical Benefits
- Accelerated Development: Move from source to raw data in minutes. By leveraging our pre-built library, your team can focus on data transformation and value creation instead of building and maintaining brittle ingestion scripts.
- Managed & Scalable Infrastructure: Arkham manages the connectors, ensuring they are always up-to-date with source API changes. The service scales automatically to handle terabytes of data without manual intervention.
- Centralized Control & Governance: Manage all source credentials and data sync schedules in one place. This unified approach simplifies security, ensures compliance, and provides clear visibility into data lineage from the very beginning.
- Built for Freshness: With native support for incremental loading and real-time streaming, you can power time-sensitive analytics and operational workflows with the freshest possible data.
Supported Sources
Our library is continuously expanding. Key categories include:
- Databases: PostgreSQL, MySQL, MongoDB
- SaaS Applications: Salesforce, SAP, Workday
- Data Warehouses: BigQuery, Redshift, Snowflake
- Event Streams: Apache Kafka, AWS Kinesis
- File Storage: Amazon S3, Azure Blob Storage, Google Cloud Storage
Related Capabilities
See how Data Connectors feed the rest of the platform: