

Data Lakehouse: La Fundación para Tu Flujo de Trabajo
Nuestro Arkham Data Lakehouse es el motor de alto rendimiento que sustenta toda la Plataforma de Datos. Combina la enorme escala de un data lake con la confiabilidad y rendimiento de un data warehouse, creando una base única y unificada para todos tus datos. Como creador, no gestionas el Lakehouse directamente; en cambio, experimentas sus beneficios a través de la velocidad, confiabilidad y potentes funciones de la cadena de herramientas de Arkham.Data Lakehouse is the high-performance engine that underpins our entire Data Platform. It combines the massive scale of a data lake with the reliability and performance of a data warehouse, creating a single, unified foundation for all your data. As a builder, you don't manage our Lakehouse directly; instead, you experience its benefits through the speed, reliability, and powerful features of Arkham's toolchain.
Cómo el Lakehouse Potencia las Herramientas de Arkham
Nuestra arquitectura Lakehouse es el “cómo” detrás de la experiencia fluida que tienes en las herramientas UI de nuestra plataforma. Cada característica técnica fundamental del Lakehouse está diseñada para habilitar directamente una parte clave de tu flujo de trabajo."how" behind the seamless experience you have in our platform's UI tools. Each core technical feature of our Lakehouse directly enables a key part of your workflow.
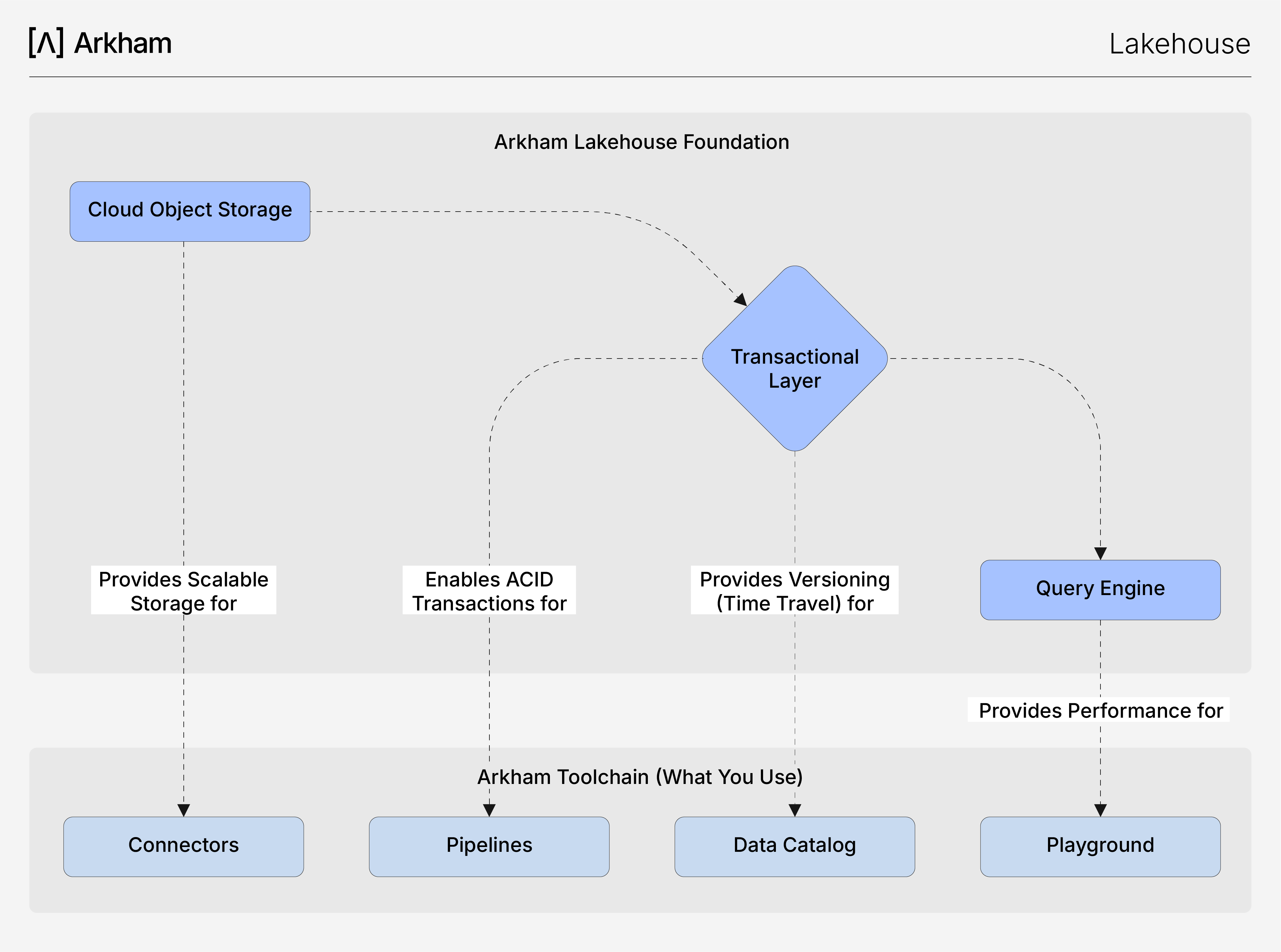
This diagram reveals how our managed Lakehouse foundation powers Arkham's toolchain, translating core technical features like ACID transactions into the reliability and speed you experience in our platform.
- Reliable Pipelines for the Pipelines Our Lakehouse brings full ACID transaction guarantees to your data transformations. When our Pipelines job runs a multi-stage pipeline, it executes as a single, atomic transaction. This means a pipeline either succeeds completely or fails cleanly, eliminating the risk of partial updates and data corruption, ensuring your Production datasets are always consistent.
- Performant Queries in the PlaygroundTus consultas en el Playground son rápidas porque el Lakehouse utiliza formatos columnarios abiertos (como Apache Parquet) y una arquitectura de cómputo desacoplada. Los datos se almacenan optimizados para consultas, y el motor de consultas puede escalar de forma independiente, asegurando una latencia baja y constante para tu análisis ad-hoc, incluso en conjuntos de datos masivos.Playground are fast because our Lakehouse uses open columnar format (like Apache Parquet) and a decoupled compute architecture. Data is stored in a query-optimized way, and the query engine can scale independently, ensuring consistently low latency for your ad-hoc analysis, even on massive datasets.
- Effortless Governance in our Data Catalog The time travel capability of the transactional layer is the foundation of our Data Catalog's governance features. Every change to a dataset creates a new version, and our Catalog maintains a full, auditable history. This allows you to inspect the state of your data at any point in time, track lineage, and debug with confidence.
- Flexible Ingestion via Connectors Nuestros Conectores pueden ingerir datos de cualquier formato de forma confiable porque el Lakehouse está diseñado para manejar cualquier formato de datos en almacenamiento de objetos rentable, mientras que la capa transaccional sigue imponiendo una fuerte validación de esquemas al escribir. Esta combinación única te brinda la flexibilidad de un data lake con las garantías de un warehouse, desde el primer paso de tu flujo de trabajo.Connectors can reliably ingest data of any shape because our Lakehouse is built to handle any data format on cost-effective object storage, while the transactional layer still enforces strong schema validation on write. This unique combination gives you the flexibility of a data lake with the guarantees of a warehouse, right from the first step of your workflow.
Arkham vs. Arquitecturas Alternativas
Para apreciar los beneficios del Lakehouse gestionado de Arkham, es útil compararlo con las arquitecturas tradicionales que los equipos de datos suelen tener que construir y mantener por sí mismos. La plataforma de Arkham está diseñada para ofrecerte las ventajas de un Lakehouse sin la complejidad de configuración y gestión.
Feature
Data Lakes
Data Warehouses
Arkham Lakehouse (Best of Both)
Storage Cost
✅ Very low (S3)
❌ High (compute + storage)
✅ Very low (S3)
Data Formats
✅ Any format (JSON, CSV, Parquet)
❌ Structured only
✅ Any format + structure
Scalability
✅ Petabyte scale
❌ Limited by cost
✅ Petabyte scale
ACID Transactions
❌ No guarantees
✅ Full ACID support
✅ Full ACID support
Data Quality
❌ No enforcement
✅ Strong enforcement
✅ Strong enforcement
Schema Evolution
❌ Manual management
❌ Rigid structure
✅ Automatic evolution
Query Performance
❌ Slow, inconsistent
✅ Fast, optimized
✅ Fast, optimized
ML/AI Support
✅ Great for ML
❌ Poor ML support
✅ Great for ML
Real-time Analytics
❌ Batch processing
✅ Real-time queries
✅ Real-time queries
Time Travel
❌ Not available
❌ Limited versions
✅ Full version history
Setup Complexity
✅ Simple (but lacks features)
❌ Complex ETL
✅ Zero (Managed by Arkham)
For a deeper dive into the technical differences between these architectures, we recommend IBM's comprehensive article on Data Warehouses, Data Lakes and Lakehouses.
Capacidades Relacionadas
- Visión General de la Plataforma de Datos: Observa cómo el Lakehouse sostiene todo el flujo de datos integrado.
- Connectors: Aprovecha la flexibilidad del Lakehouse para ingerir cualquier formato de datos.
- Pipelines: Construye pipelines confiables respaldados por las garantías de transacciones ACID del Lakehouse.
- Catálogo de Datos: Gobierna y versiona automáticamente tus datos con las capacidades de Viaje en el Tiempo del Lakehouse.
- Playground: Ejecuta consultas de alto rendimiento en conjuntos masivos de datos gracias al motor optimizado del Lakehouse.
SÍGUENOS