

Data Lakehouse: Our Foundation for Your Workflow
Our Data Lakehouse is the high-performance engine that underpins our entire Data Platform. It combines the massive scale of a data lake with the reliability and performance of a data warehouse, creating a single, unified foundation for all your data. As a builder, you don't manage our Lakehouse directly; instead, you experience its benefits through the speed, reliability, and powerful features of Arkham's toolchain.
How our Lakehouse Powers Arkham's Tools
Our Lakehouse architecture is the "how" behind the seamless experience you have in our platform's UI tools. Each core technical feature of our Lakehouse directly enables a key part of your workflow.
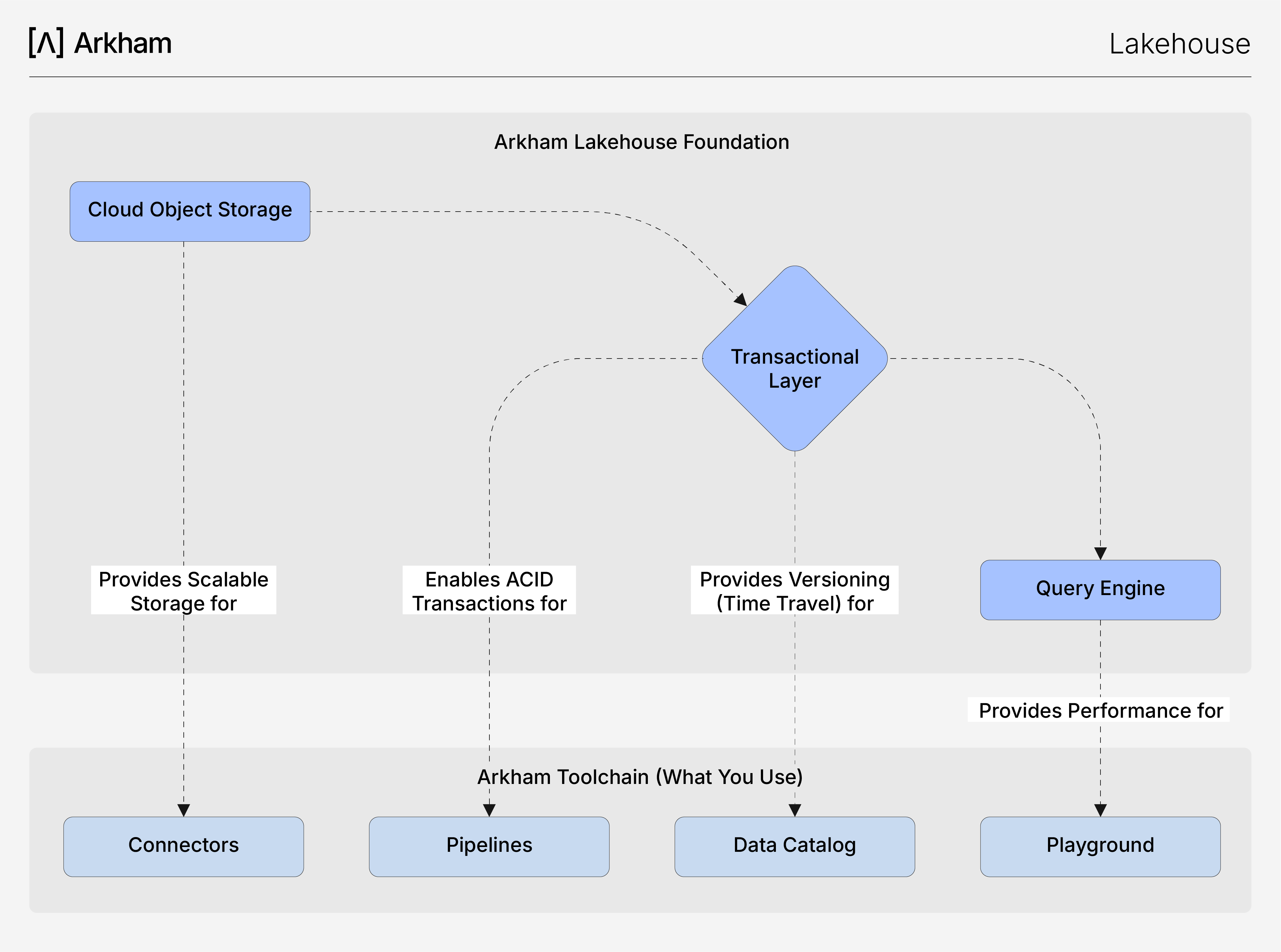
This diagram reveals how our managed Lakehouse foundation powers Arkham's toolchain, translating core technical features like ACID transactions into the reliability and speed you experience in our platform.
- Reliable Pipelines for the Pipelines Our Lakehouse brings full ACID transaction guarantees to your data transformations. When our Pipelines job runs a multi-stage pipeline, it executes as a single, atomic transaction. This means a pipeline either succeeds completely or fails cleanly, eliminating the risk of partial updates and data corruption, ensuring your Production datasets are always consistent.
- Performant Queries in the Playground Your queries in our Playground are fast because our Lakehouse uses open columnar format (like Apache Parquet) and a decoupled compute architecture. Data is stored in a query-optimized way, and the query engine can scale independently, ensuring consistently low latency for your ad-hoc analysis, even on massive datasets.
- Effortless Governance in our Data Catalog The time travel capability of the transactional layer is the foundation of our Data Catalog's governance features. Every change to a dataset creates a new version, and our Catalog maintains a full, auditable history. This allows you to inspect the state of your data at any point in time, track lineage, and debug with confidence.
- Flexible Ingestion via Connectors Our Connectors can reliably ingest data of any shape because our Lakehouse is built to handle any data format on cost-effective object storage, while the transactional layer still enforces strong schema validation on write. This unique combination gives you the flexibility of a data lake with the guarantees of a warehouse, right from the first step of your workflow.
Arkham vs. Alternative Architectures
To appreciate the benefits of Arkham's managed Lakehouse, it's helpful to compare it to other traditional architectures that data teams often have to build and maintain themselves. Arkham's platform is designed to give you the advantages of a Lakehouse without the setup and management overhead.
Feature
Data Lakes
Data Warehouses
Arkham Lakehouse (Best of Both)
Storage Cost
✅ Very low (S3)
❌ High (compute + storage)
✅ Very low (S3)
Data Formats
✅ Any format (JSON, CSV, Parquet)
❌ Structured only
✅ Any format + structure
Scalability
✅ Petabyte scale
❌ Limited by cost
✅ Petabyte scale
ACID Transactions
❌ No guarantees
✅ Full ACID support
✅ Full ACID support
Data Quality
❌ No enforcement
✅ Strong enforcement
✅ Strong enforcement
Schema Evolution
❌ Manual management
❌ Rigid structure
✅ Automatic evolution
Query Performance
❌ Slow, inconsistent
✅ Fast, optimized
✅ Fast, optimized
ML/AI Support
✅ Great for ML
❌ Poor ML support
✅ Great for ML
Real-time Analytics
❌ Batch processing
✅ Real-time queries
✅ Real-time queries
Time Travel
❌ Not available
❌ Limited versions
✅ Full version history
Setup Complexity
✅ Simple (but lacks features)
❌ Complex ETL
✅ Zero (Managed by Arkham)
For a deeper dive into the technical differences between these architectures, we recommend IBM's comprehensive article on Data Warehouses, Data Lakes and Lakehouses.
Related Capabilities
- Data Platform Overview: See how our Lakehouse underpins the entire integrated data workflow.
- Connectors: Leverage our Lakehouse's flexibility to ingest any data format.
- Pipelines: Build reliable pipelines backed by the ACID transaction guarantees of our Lakehouse.
- Data Catalog: Automatically govern and version your data with our Lakehouse's Time Travel capabilities.
- Playground: Run high-performance queries on massive datasets thanks to our Lakehouse's optimized engine.
FOLLOW US