

Overview: Data Platform
Transforming operations with AI begins with the most critical asset: your data. But in most organizations, data is fragmented across dozens of systems, making it nearly impossible to establish a trusted, unified view. Arkham's Data Platform is engineered to solve this foundational challenge. It is one of the core pillars of our platform, designed to unify your disparate data sources into a single source of truth, ready for advanced analytics and AI.
Instead of wrestling with a complex web of commodity cloud services, our Data Platform provides builders with a fully-managed, UI-driven environment to move from raw data to production-ready assets with unparalleled speed. Our integrated toolchain—Connectors, Pipelines, Data Catalog, Playground, and our AI copilot TARS—empowers your teams to focus on creating value, not managing infrastructure.
Arkham's Platform Home screen, where our AI copilot TARS proactively guides builders with contextual starting points, accelerating the journey from raw data to production-ready assets.
A Framework for Integrated Data Workflows
Our Data Platform is built on three foundational pillars that work in concert to deliver reliable, AI-ready data.
- Data Connectivity: We provide a comprehensive suite of managed Connectors to reliably and automatically ingest data from any source system. This eliminates the need for brittle, custom ingestion scripts and accelerates the first mile of any data project.
- Data Transformation: Our Pipelines offers a transparent, visual environment for transforming raw data into clean, production-grade assets. By representing logic as a graph, we make data lineage explicit and data quality easier to manage.
- Data Management: At the core of the platform is our Data Catalog, which provides a governed, three-tiered registry for all data assets. Powered by Arkham's Lakehouse, this ensures every dataset is versioned, auditable, and secure.
Core Components
Our Data Platform is comprised of several integrated services that work together to deliver on the promise of a unified data foundation.
- Connectors: Automate data ingestion from any source system with a library of pre-built, production-grade integrations.
- Pipelines: A visual, canvas-based environment for orchestrating complex data transformation pipelines.
- Data Catalog: Our centralized registry for discovering, understanding, and governing all data assets in your organization.
- Playground: An interactive Trino SQL editor for exploring and validating trusted, production-ready datasets.
- Lakehouse: Our underlying storage and compute architecture that guarantees data quality, reliability, and performance across our platform.
Core Concepts
Concept
Description
Dataset
A collection of data, similar to a table in a database, that is registered and versioned in our Data Catalog.
Staging Tier
Contains raw, un-validated data ingested directly from source systems by Connectors.
Production Tier
Contains clean, validated, and transformed Datasets ready for consumption by analytics and AI models.
Data Lineage
Tab per Dataset showing the flow of data from its source to its final destination consumed through Workbooks or other applications.
Pipeline
A versioned, executable graph in our Pipelines that transforms input datasets into new output datasets.
Builder's Workflow: From Ingestion to Insight
Arkham's architecture enables security, reliability and operational excellence in data workflows by design. The following diagram illustrates this prescriptive path, from initial data connection to final consumption, bringing all the core components together in a unified workflow.
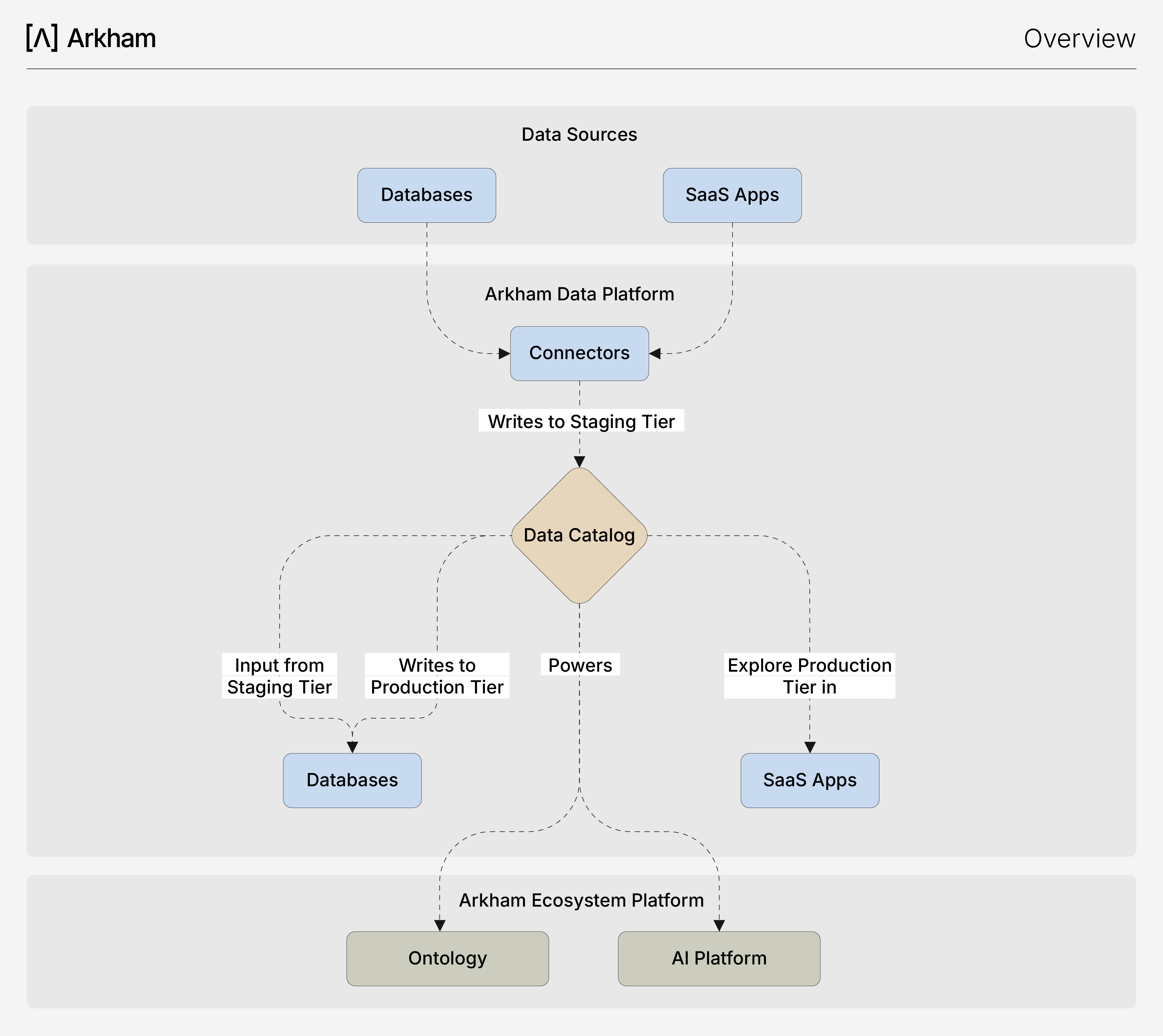
This diagram illustrates our platform's end-to-end data lifecycle, demonstrating how integrated components guide data from ingestion to consumption in a single, governed workflow.
- Automated Ingestion: Your journey begins in Connectors, where you configure connections to your source systems through a simple UI. Arkham handles the managed ingestion, reliably landing your raw data into a Staging dataset in our Data Catalog. This gives you an immediate, queryable snapshot of your source data without any manual scripting.
- Visual Transformation: With your data in the Staging Tier, you use our Pipelines to sanitize, transform and validate it. This canvas-based tool lets you visually construct complex transformations. As you build, each transformation can be previewed, validated, and saved. The final output is published as a clean, reliable Production dataset, again, automatically registered in our Data Catalog.
- Instant Discovery and Exploration: Our Data Catalog acts as your central registry, automatically indexing both your Staging and Production datasets. From our UI, you can see dataset schemas, track lineage, and manage access. For immediate validation or ad-hoc analysis, you can jump directly into our Playground, an integrated Trino SQL environment with Trino dialect, to query any dataset.
- Consumption & Enrichment: Your high-quality Production datasets are now the trusted foundation for all downstream applications. They are consumed by the integrated AI Platform to train models and by business intelligence tools for analytics. In turn, our AI Platform produces new, valuable ML Model Datasets (e.g., predictions, performance metrics) that are registered back into our Data Catalog, creating a virtuous cycle of data enrichment.
This prescriptive workflow ensures that your data is always governed, your pipelines are robust, and your development cycles are short, enabling you to build and iterate faster.
Related Capabilities
Arkham's Data Platform serves as the foundation for several other key capabilities in the Arkham ecosystem.
- AI Platform: Consumes production-grade datasets from our Data Platform to train models and generate insights.
- Ontology: Maps datasets into business valuable units.
- Governance: Provides the framework for securing and auditing all assets created and managed within our Data Platform.
- TARS: Our AI Copilot assists in every component of our Data Platform, from generating Trino SQL to explaining pipeline logic.
FOLLOW US