

ML Hub: Our Notebook Environment for Production ML
From a promising model in a Jupyter notebook to a governed, production-ready asset is where most machine learning projects fail. Code is rewritten, data lineage is lost, and deployment becomes a complex, manual process. This friction prevents organizations from realizing the full value of their ML investments.
Arkham's ML Hub is engineered to eliminate this friction. It provides a powerful, Python-based notebook interface that is deeply integrated with the rest of our Arkham platform. Here, you can move seamlessly from data preparation to deployment within a single, governed environment, using either custom code or our accelerated AutoML frameworks. Once your model is deployed, monitoring its performance and interacting with the rest of the MLOps lifecycle is as simple as navigating to the model details section.
Our ML Hub's template gallery, which provides a library of pre-built notebooks for common use cases, accelerating the path from concept to production model.
Notebooks
Arkham's ML Hub provides a powerful, Python-based notebook environment that combines the familiar Jupyter notebook interface with deep platform integration. Our notebook environment automatically handles compute provisioning and scaling, so you can focus on building models rather than managing infrastructure.
Most importantly, our notebooks are natively integrated with our platform's data layer. You have direct access to read and write data from our Lakehouse. This integration eliminates the friction of data access, allowing you to load production datasets, write model outputs, and create training datasets—all within a single, governed environment.
Our ML Hub Workflow: From Data to Deployed Model
Our ML Hub is designed to support the end-to-end machine learning lifecycle within a single, governed environment. The diagram below illustrates the recommended workflow:

This diagram illustrates our ML Hub's end-to-end workflow, showing the seamless path from selecting a Notebook Template to deploying a versioned model whose outputs are automatically monitored and ready for analysis.
The data scientist workflow is structured to ensure traceability and rapid development:
- Select a Notebook Template: The journey begins by selecting a pre-built, use-case-specific Notebook Template directly that provides all the boilerplate code and a best-practice structure. In addition to our production-ready model templates, we also offer a Data Exploration template for quick-starting ad-hoc analysis.
- Connect to Your Data: The template contains pre-written code to connect to the Data Catalog. You simply provide the ID of your trusted Production Dataset to load it into the notebook.
- Configure the Model Class: The notebook comes pre-loaded with the appropriate (e.g., Classification, Regression, Forecasting). You configure its parameters in code to leverage our AutoML framework for your specific dataset and business problem although reasonable starters are already provided.
- Train and Select: Triggering the run launches an automated AutoML pipeline. You review the resulting leaderboard of models and select the best candidate for deployment.
- Version and Operationalize: Once you have a chosen model, you save it as a new, immutable version. From here, you can operationalize it by scheduling a recurring batch inference job. The health and performance of these jobs can be tracked in real-time in the Pipeline Monitoring service. Each successful run publishes its outputs—the inference results, train/test data, and performance metrics—as new, versioned datasets in the Data Catalog.
- Model Monitoring: after deploying your model, you can schedule a recurring monitoring job to continuously track its performance and detect data drift. Our monitoring system automatically compares your model's predictions against ground truth data and analyzes input data distributions for signs of drift. These monitoring jobs generate Performance and Data Drift Metrics as versioned datasets in the Data Catalog, providing a historical record of your model's health over time. All monitoring job executions are automatically tracked in Pipeline Monitoring.
- Retraining: When monitoring metrics indicate performance degradation or significant data drift, or when new training data becomes available, you can initiate a retraining workflow directly from the model details page. This process clones your original notebook template with the updated dataset, allowing you to leverage the same AutoML framework to produce an improved model version. Once retrained and validated, you can version the new model and seamlessly replace the previous version in your production inference jobs, ensuring your models continuously adapt to changing data patterns.
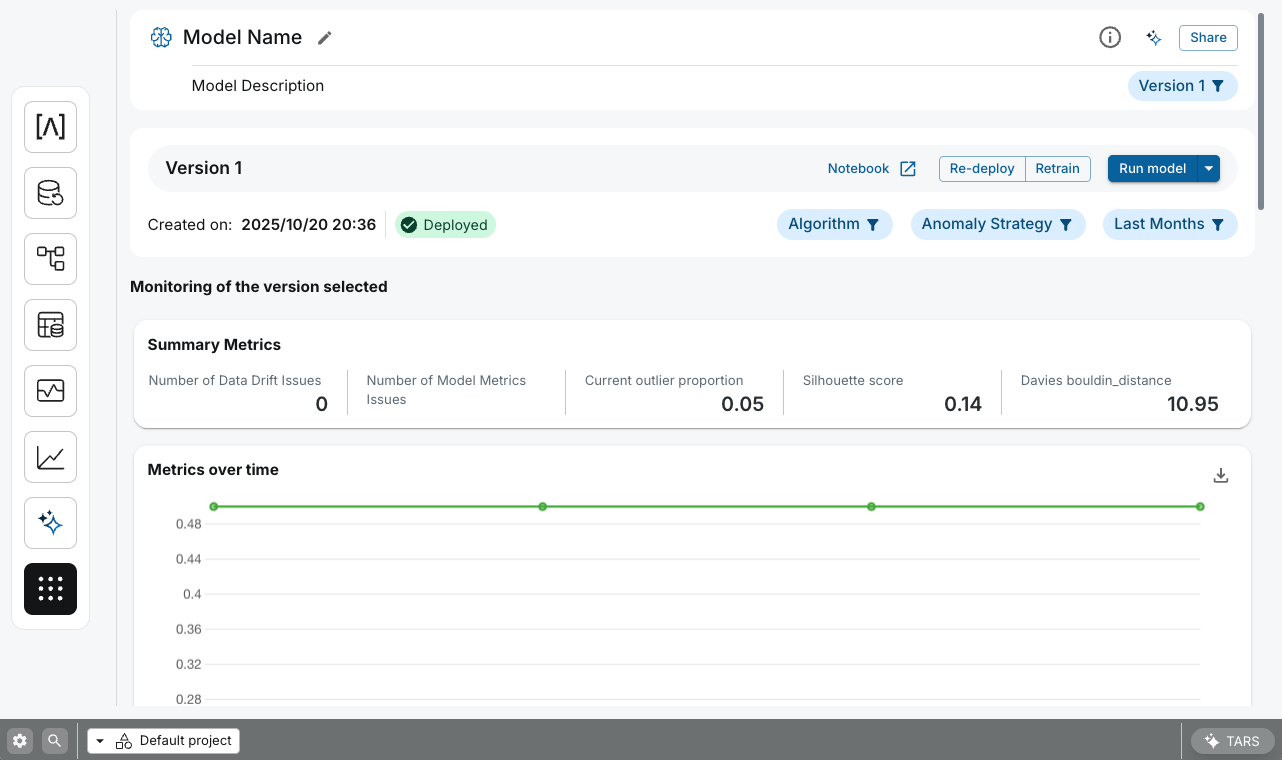
Our ML Hub's model details interface provides essential actions to interact with the complete model lifecycle and comprehensive monitoring capabilities, offering visibility into performance metrics, data drift detection, and monitoring job execution history.
🤖 AI-Assisted Development with TARS
At this stage, TARS serves as a powerful co-pilot, automating boilerplate code and accelerating the research process. It's deeply integrated into the notebook environment, capable of understanding the context of the code and data on screen. Ask it to:
Generate Code: "TARS, load the @customer_churn_training_data dataset into a pandas DataFrame."Explore Data: "TARS, what's the distribution of the age column in this dataset?"
Debug and Explain: "TARS, explain this block of code to me."
Key Features for Builders
- Seamless Data Integration: Never move data again. ML Hub's direct integration with our Data Catalog means you can securely access any dataset in our platform without needing to manage credentials or data transfers.
- Integrated Model Lifecycle Management: Our ML Hub has built-in support for model versioning and one-click deployment through our template-based framework. This streamlines the path to production, making it easy to manage and govern your models from experimentation to production.
- AutoML-Powered Model Classes: Accelerate your projects with our "glass-box" Model Classes. These classes enable hyper-optimization capabilities through our AutoML engine to automate the most time-consuming parts of the ML lifecycle and produce a leaderboard of high-quality models. Key templates include:
Classification: Predict a categorical outcome, such as customer churn or lead conversion.
Regression: Forecast a continuous value, like sales revenue or product demand.
Forecasting: Predict future values in a time series, ideal for inventory management or financial planning.
Anomaly Detection: Identify rare events or outliers that deviate from the norm, critical for fraud detection or equipment monitoring.
Anomaly Detection Timeseries: Detect anomalies in sequential data, such as identifying unusual patterns in server logs or financial transactions over time.
Clustering: Group similar data points together to discover hidden segments, such as customer personas or product affinities.
From Model to Insight: Visualizing Results in Workbooks
Deploying a model isn't the end of the journey. By scheduling inference jobs, you create a rich, historical record of your model's performance as datasets in our Data Catalog.
You can connect directly to these model output datasets in Workbooks to:
- Monitor Performance: Track your model's accuracy, precision, or other key metrics over time against live data.
- Analyze Predictions: Explore and segment your model's predictions to uncover new insights.
- Create "What-If" Scenarios: Build interactive dashboards that allow business users to change input parameters and see the model's response, turning your ML model into a dynamic decision-making tool.
This seamless integration between our ML Hub and Workbooks closes the loop on the MLOps lifecycle, moving your model from a black box in a notebook to an interactive and explainable tool for your business.
Related Capabilities
- AI Platform Overview: See how our ML Hub fits into the end-to-end machine learning lifecycle.
- Data Catalog: The source of the trusted Production Datasets used to train your models.
- Workbooks: Visualize your model's outputs and monitor its performance over time.
- TARS: Accelerate your notebook development with an AI-powered co-pilot for code generation and debugging.
FOLLOW US