

Pipelines: Visually Orchestrate Data Transformations
Black-box data pipelines are a primary source of data quality issues. When transformation logic is trapped in thousands of lines of disconnected SQL scripts, it becomes difficult to debug, impossible for stakeholders to understand, and a nightmare to maintain.
Arkham's Pipelines is engineered to solve this. It replaces opaque, imperative scripts with a transparent, visual canvas for orchestrating complex data transformations. Here, you build pipelines by composing powerful transformations in an interactive graph, where data lineage is explicit and automatically tracked. This allows builders to move from raw, staging datasets to production-ready assets with unparalleled clarity and speed.
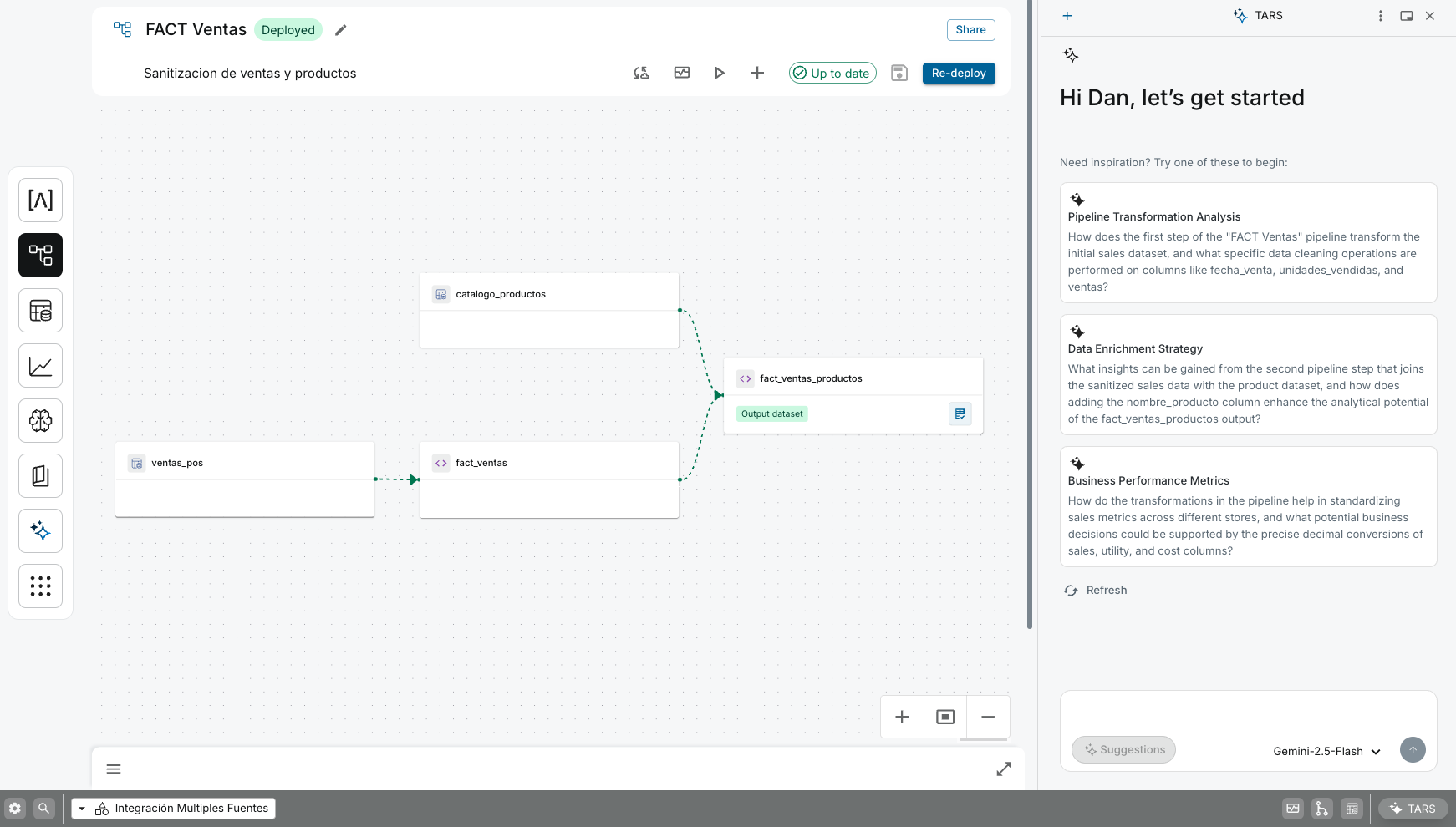
Our Pipelines visual canvas, where builders orchestrate transformations as a graph, making data lineage explicit and simplifying the development of complex data workflows.
How It Works: A Node-Based Workflow
Our Pipelines represents your entire transformation logic as a directed acyclic graph (DAG). Each node in the graph is a dataset, and each connection represents a transformation that creates a new dataset from its parents. The development lifecycle is visual and interactive:
- Add Datasets: You start by adding existing datasets from our Data Catalog onto the canvas. Typically, your journey will begin with the Staging Datasets created by Connectors.
- Apply Transformations: Select source nodes and choose a transformation. You can use a UI-driven helper for common operations like joins and unions or write a custom SQL query with Trino dialect in the embedded editor for more complex logic. The editor supports referencing other nodes in the pipeline (e.g.,
SELECT * FROM @forecast_sales). - Preview and Iterate: Before committing, you can instantly preview the results of your transformation. Our platform uses a session compute cluster to run the query on sample data, allowing you to validate your logic in real-time.
- Save and Version: Once you are satisfied with the preview, you apply the step, which creates a new dataset node on the canvas. Saving the pipeline creates a new, immutable version, ensuring that your work is tracked and reproducible.
- Deploy: When your pipeline is complete, you deploy a specific version. The deployed version can be run manually or set to execute on a recurring schedule, publishing a clean, validated Production Dataset to our Data Catalog.
🤖 AI-Assisted Transformation with TARS
At this step, you can ask TARS to accelerate your work by generating complex Trino SQL for you. Instead of writing the query manually, you can provide a prompt like:
"Suggest a SQL query to join@dataset_Aand@dataset_Bon the user_id column, and filter for users in Mexico."
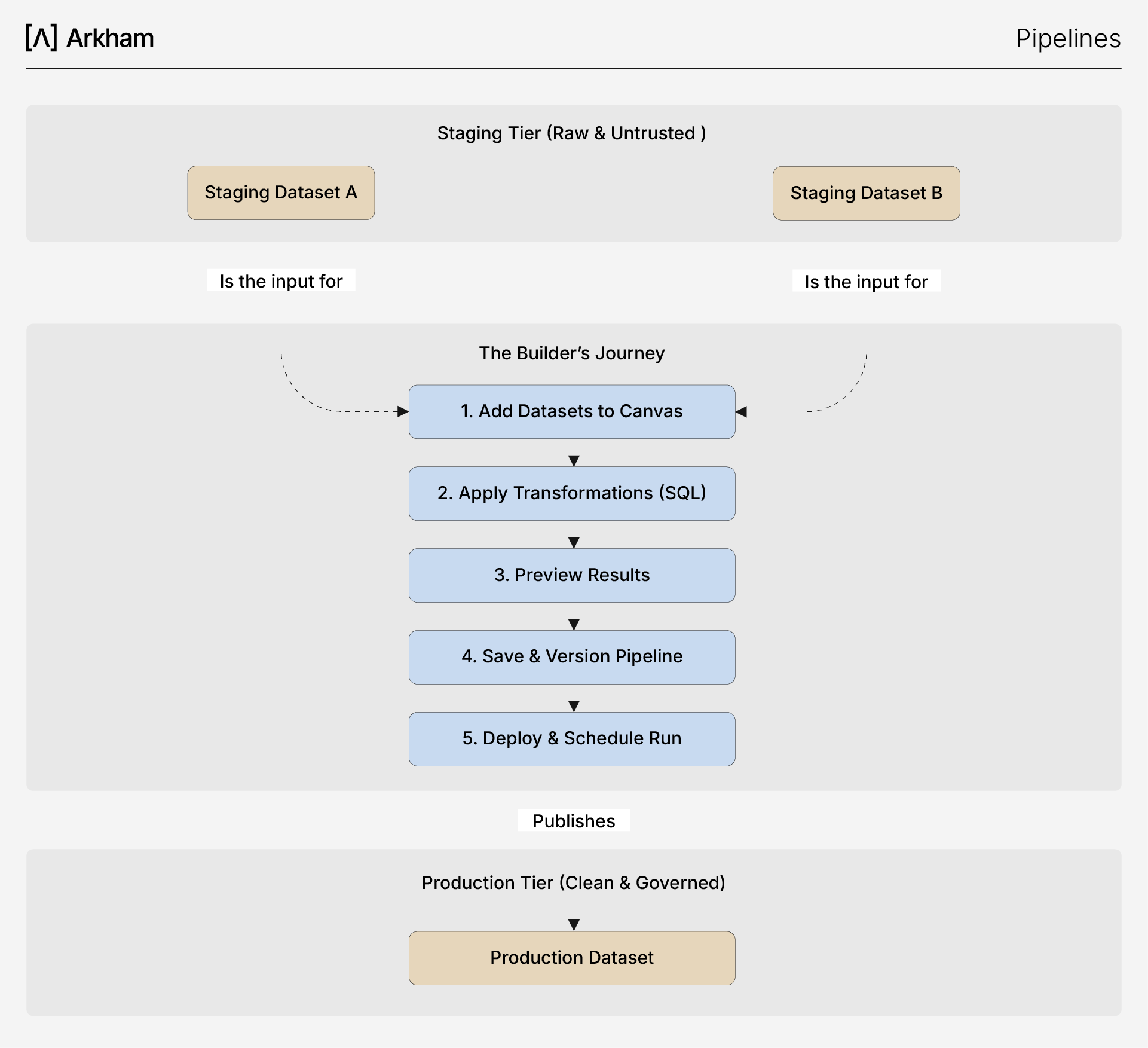
This diagram outlines the five-step builder's journey in our Pipelines, from adding raw Staging data to the canvas to deploying a versioned pipeline that publishes a trusted Production dataset.
Key Technical Benefits
- Accelerated Development: The visual interface and live previews dramatically reduce development time. What used to require cycles of coding, running, and debugging can now be done in minutes.
- Clarity and Lineage: The tab makes even the most complex pipelines easy to understand. Data lineage is explicit and automatically tracked, simplifying debugging and impact analysis.
- Reproducibility and Governance: Every saved change creates a new, immutable version of the pipeline. You can always roll back to a previous version or inspect the exact logic that produced a given dataset, ensuring full auditability.
- Scalability: While the interface is visual, the execution is not. When you deploy a pipeline, Arkham runs it on a scalable, managed compute engine capable of processing terabytes of data efficiently.
Related Capabilities
- Data Platform Overview: See how our Pipelines fits into the end-to-end data workflow.
- Data Catalog: The source for your input datasets and the destination for your new Production-grade assets.
- Connectors: The upstream process that ingests the raw Staging data used in your pipelines.
- Playground: The ideal place to query, explore, and validate the new Production datasets you've created.
- TARS: Your AI co-pilot for generating SQL with Trino Dialect, debugging errors, and checking pipeline status.
FOLLOW US