

Catálogo de Datos: La Fuente Única de Verdad para los Datos
"¿Dónde están los datos?" En la mayoría de las organizaciones, esta simple pregunta es el inicio de una investigación forense que consume mucho tiempo, a través de tablas no documentadas, historiales de Slack y paneles de inteligencia empresarial contradictorios. El resultado es esfuerzo duplicado, métricas inconsistentes y falta de confianza en los datos.
El Catálogo de Datos de Arkham está diseñado para ser la fuente definitiva de verdad para todos los activos de datos en tu organización. No es un registro pasivo; es un componente central y activo de tu estrategia de datos. Al ingerir metadatos automáticamente y organizar los activos en capas claras de Preparación, Producción y Modelos de ML, el Catálogo proporciona un camino confiable, buscable y gobernado para que los creadores encuentren y usen los datos adecuados para el trabajo.Staging, Production, and ML Model tiers, the Catalog provides a reliable, searchable, and governed path for builders to find and use the right data for the job.
Cómo Funciona: Las Tres Capas de Datos
Nuestro Catálogo de Datos está diseñado alrededor de un sistema de tres capas para garantizar la calidad de los datos y proporcionar un ciclo de vida claro para tus activos de datos. Esta estructura es gestionada automáticamente por nuestra plataforma mientras usas las herramientas principales para desarrolladores.
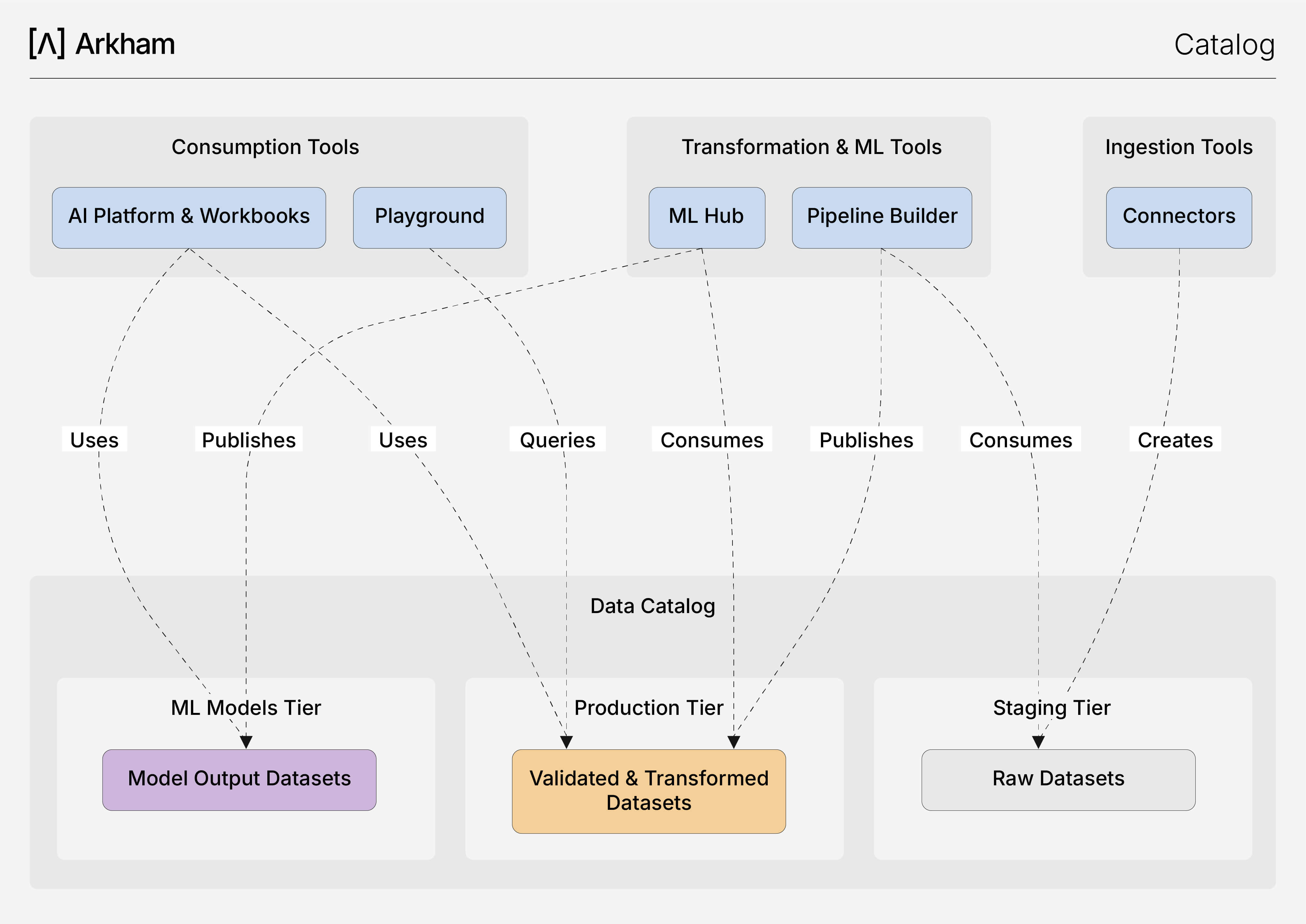
- Capa de Preparación: Esta capa contiene datos en bruto, no validados, ingeridos directamente desde tus sistemas fuente mediante Conectores. Los datasets de preparación ofrecen una instantánea inmediata y consultable de tus fuentes y sirven como entrada directa para tus pipelines de transformación.
- Capa de Producción: Esta capa contiene los datasets limpios, validados y transformados que son el resultado del Pipeline Builder. Estos son tus activos de datos de alta calidad y confianza, listos para su consumo.
- Capa de Modelos de ML: Esta capa contiene los resultados directos de tus modelos de aprendizaje automático desde el ML Hub. Los datasets aquí incluyen resultados de inferencia, datos de entrenamiento/prueba y métricas de desempeño del modelo, proporcionando un registro completo y auditable de la actividad de tu modelo.
🤖 AI-Assisted Discovery with TARS
The Data Catalog is where TARS's deep understanding of your data landscape shines. It acts as an intelligent discovery tool, saving you hours of manual exploration. You can ask complex questions in natural language:
"Show me the lineage for the production_orders dataset. What pipelines create it and what workbooks consume it?"TARS can also help you explore schemas, profile columns, and even generate sample queries, making data discovery faster and more intuitive.
Principales Beneficios Técnicos
- Ciclo de Vida Claro de los Datos: El sistema de tres capas proporciona un camino claro y prescriptivo para todo el desarrollo de datos, desde la ingesta en bruto hasta los insights impulsados por ML.
- Descubrimiento Automático de Datos: El catálogo registra automáticamente datasets de todas las fuentes—Conectores, Pipeline Builder y ML Hub—asegurando que siempre sea un reflejo actualizado de tu Lakehouse.
- Trazabilidad y Procedencia de Datos: Proporciona un grafo completo de trazabilidad para cada activo de datos, permitiéndote rastrear los datos desde su fuente hasta su consumo. Esto es crítico para análisis de impacto, análisis de causa raíz y cumplimiento normativo.
- Control de Acceso Granular: Protege tus datos con herramientas robustas de gobernanza. Puedes aplicar Listas de Control de Acceso (ACLs) directamente a los datasets, asegurando que usuarios y roles solo tengan permiso para ver y consultar los datos que están autorizados a acceder.
- Integración con el Ecosistema Arkham: El Catálogo de Datos es el núcleo central que conecta todos los demás componentes, desde Conectores hasta Playground, permitiendo una experiencia fluida para los creadores.
Capacidades Relacionadas
- Visión General de la Plataforma de Datos: Entiende cómo el Catálogo de Datos actúa como el núcleo central en el flujo de trabajo de datos.
- Conectores: La fuente de todos los datasets en la capa de Preparación.
- Pipeline Builder: Consume datos de la capa de Preparación y publica datasets confiables en la capa de Producción.
- Playground: La herramienta principal para explorar, consultar y validar datasets en el Catálogo.
- TARS: Tu copiloto de IA para el descubrimiento inteligente de datos, exploración de esquemas y rastreo de trazabilidad.