

Pipeline Builder: Orquesta Visualmente las Transformaciones de Datos
Los pipelines de datos como “caja negra” son una fuente principal de problemas de calidad de datos. Cuando la lógica de transformación está atrapada en miles de líneas de scripts SQL desconectados, se vuelve difícil de depurar, imposible para los interesados entender, y una pesadilla de mantener.
El Pipeline Builder de Arkham está diseñado para resolver esto. Reemplaza los scripts opacos e imperativos con un lienzo visual y transparente para orquestar transformaciones complejas de datos. Aquí construyes pipelines componiendo transformaciones poderosas en un grafo interactivo, donde la trazabilidad de datos es explícita y se rastrea automáticamente. Esto permite avanzar de datasets en bruto y preparación a activos listos para producción con claridad y rapidez sin igual.
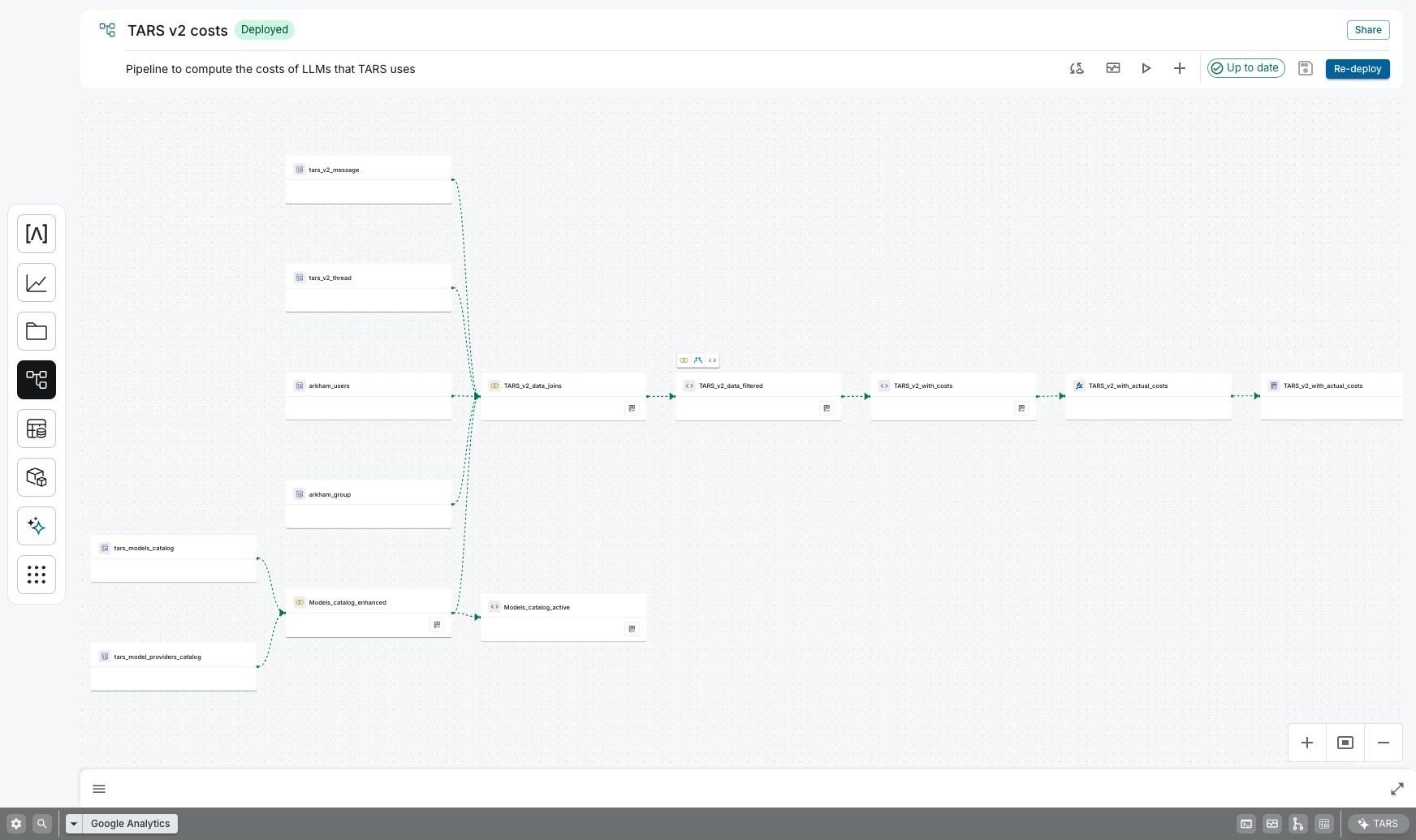
Cómo Funciona: Un Flujo de Trabajo Basado en Nodos
El Pipeline Builder representa toda tu lógica de transformación como un grafo dirigido acíclico (DAG). Cada nodo en el grafo es un conjunto de datos, y cada conexión representa una transformación que crea un nuevo conjunto de datos a partir de sus nodos padres.
El ciclo de desarrollo es visual e interactivo:
- Agrega Datasets: Comienzas agregando datasets existentes desde el Catálogo de Datos al lienzo. Típicamente, tu recorrido iniciará con los datasets de preparación creados por los Conectores
- Aplica Transformaciones: Selecciona nodos fuente y elige una transformación. Puedes usar un asistente guiado por UI para operaciones comunes como joins y unions, o escribir una consulta SQL personalizada en el editor embebido para lógica más compleja. El editor soporta referencias a otros nodos en el pipeline (por ejemplo, SELECT * FROM @forecast_sales).
SELECT * FROM @forecast_sales).
🤖 Transformación asistida por AI con TARS
En este paso, puede pedirle a TARS que acelere su trabajo generando SQL complejo para usted. En lugar de escribir la consulta manualmente, puede proporcionar un mensaje como:
“Sugerir una consulta SQL para unirse@dataset_Ay@dataset_Ben elusuario_idcolumna y filtro para usuarios enMéxico.” TARS generará el SQL correcto directamente en su editor.
- Preview and Iterate: Before committing, you can instantly preview the results of your transformation. Our platform uses a session compute cluster to run the query on sample data, allowing you to validate your logic in real-time.
- Save and Version: Once you are satisfied with the preview, you apply the step, which creates a new dataset node on the canvas. Saving the pipeline creates a new, immutable version, ensuring that your work is tracked and reproducible.
- Deploy: When your pipeline is complete, you deploy a specific version. The deployed version can be run manually or set to execute on a recurring schedule, publishing a clean, validated Production Dataset to the Data Catalog.
Principales Beneficios Técnicos
- Desarrollo Acelerado: La interfaz visual y las previsualizaciones en vivo reducen drásticamente el tiempo de desarrollo. Lo que antes requería ciclos de codificación, ejecución y depuración ahora puede hacerse en minutos.
- Claridad y Trazabilidad: La vista basada en grafos facilita la comprensión incluso de los pipelines más complejos. La trazabilidad de datos es explícita y se rastrea automáticamente, simplificando la depuración y el análisis de impacto.
- Reproducibilidad y Gobernanza: Cada cambio guardado crea una nueva versión inmutable del pipeline. Siempre puedes regresar a una versión anterior o inspeccionar la lógica exacta que produjo un conjunto de datos, garantizando auditoría completa.
- Escalabilidad: Aunque la interfaz es visual, la ejecución no lo es. Cuando despliegas un pipeline, Arkham lo ejecuta en un motor de cómputo escalable y gestionado, capaz de procesar terabytes de datos de forma eficiente.
Capacidades Relacionadas
- Visión General de la Plataforma de Datos: Observa cómo el Pipeline Builder encaja en el flujo de datos de extremo a extremo.
- Catálogo de Datos: La fuente de tus datasets de entrada y el destino para tus nuevos activos de nivel producción.
- Conectores: El proceso inicial que ingiere los datos en bruto de preparación que usas en tus pipelines.
- Playground: El lugar ideal para consultar, explorar y validar los nuevos conjuntos de datos de Producción que has creado.
- TARS: Tu copiloto de IA para generar SQL, depurar errores y verificar el estado del pipeline.