

Plataforma de Datos: La base esencial para tu transformación en IA
Transformar tus operaciones con IA empieza por el activo más valioso: tus datos. Sin embargo, en la mayoría de las empresas, los datos están dispersos en múltiples sistemas, lo que dificulta contar con una visión única y confiable. La Plataforma de Datos de Arkham nace para resolver este reto fundamental. Es uno de los pilares centrales de nuestra solución, diseñada para consolidar tus fuentes de datos en una única fuente de verdad, preparada para análisis avanzados e inteligencia artificial.
En lugar de complicarte con una maraña de servicios en la nube genéricos, Arkham ofrece a los equipos técnicos un entorno totalmente gestionado, con una interfaz intuitiva, que permite transformar datos en bruto en activos listos para producción con una velocidad incomparable. Nuestra cadena de herramientas integrada —Conectores, Pipeline Builder, Catálogo de Datos, Playground y el copiloto de IA TARS— empodera a tus equipos para que se concentren en generar valor, sin preocuparse por la infraestructura.
Un marco para flujos de trabajo de datos integrados
Nuestra Plataforma de Datos se basa en tres pilares fundamentales que trabajan en conjunto para entregar datos confiables y listos para IA.
- Conectividad de Datos: Ofrecemos una suite completa de conectores gestionados para ingerir datos automáticamente y con fiabilidad desde cualquier sistema origen. Esto elimina la necesidad de scripts de ingestión personalizados y frágiles, acelerando la primera etapa de cualquier proyecto de datos.
- Transformación de datos: Pipeline Builder ofrece un entorno visual y transparente para transformar datos en bruto en activos limpios y listos para producción. Al representar la lógica como un grafo, hacemos explícito el linaje de los datos y facilitamos la gestión de su calidad.
- Gestión de Datos: En el corazón de la plataforma está el Catálogo de Datos, que proporciona un registro gobernado y en tres niveles para todos los activos de datos. Gracias a nuestra arquitectura Lakehouse, cada conjunto de datos está versionado, auditado y asegurado.
Componentes clave
Nuestra Plataforma de Datos se compone de varios servicios integrados que trabajan juntos para cumplir la promesa de una base de datos unificada.
- Conectores: Automatizan la ingestión de datos desde cualquier sistema con una biblioteca de integraciones preconstruidas y listas para producción.
- Pipeline Builder: Un entorno visual basado en lienzo para orquestar pipelines complejos de transformación de datos.
- Catálogo de Datos: El registro centralizado para descubrir, entender y gobernar todos los activos de datos en tu organización.
- Playground: Un editor SQL interactivo para explorar y validar conjuntos de datos confiables y listos para producción.
- Lakehouse: La arquitectura subyacente de almacenamiento y cómputo que garantiza calidad, confiabilidad y rendimiento en toda la plataforma.
Conceptos clave
Concepto
Descripción
Dataset
Colección de datos, similar a una tabla en una base de datos, registrada y versionada en el Catálogo de Datos.
Staging Tier
Contiene datos en bruto, sin validar, ingeridos directamente desde los sistemas origen mediante los conectores.
Production Tier
Contiene conjuntos de datos limpios, validados y transformados, listos para análisis y modelos de IA.
Linaje de Datos
Un grafo generado automáticamente que muestra el flujo de los datos desde su origen hasta su destino final.
Pipeline
Un grafo versionado y ejecutable en Pipeline Builder que transforma datasets de entrada en nuevos datasets de salida.
El flujo de trabajo en Pipeline Builder: de la ingestión al insight
Nuestra arquitectura garantiza desde el diseño seguridad, confiabilidad y excelencia operativa en los flujos de trabajo de datos. El siguiente diagrama ilustra este proceso estructurado, que va desde la conexión inicial de datos hasta su consumo final, integrando todos los componentes clave en un flujo unificado.
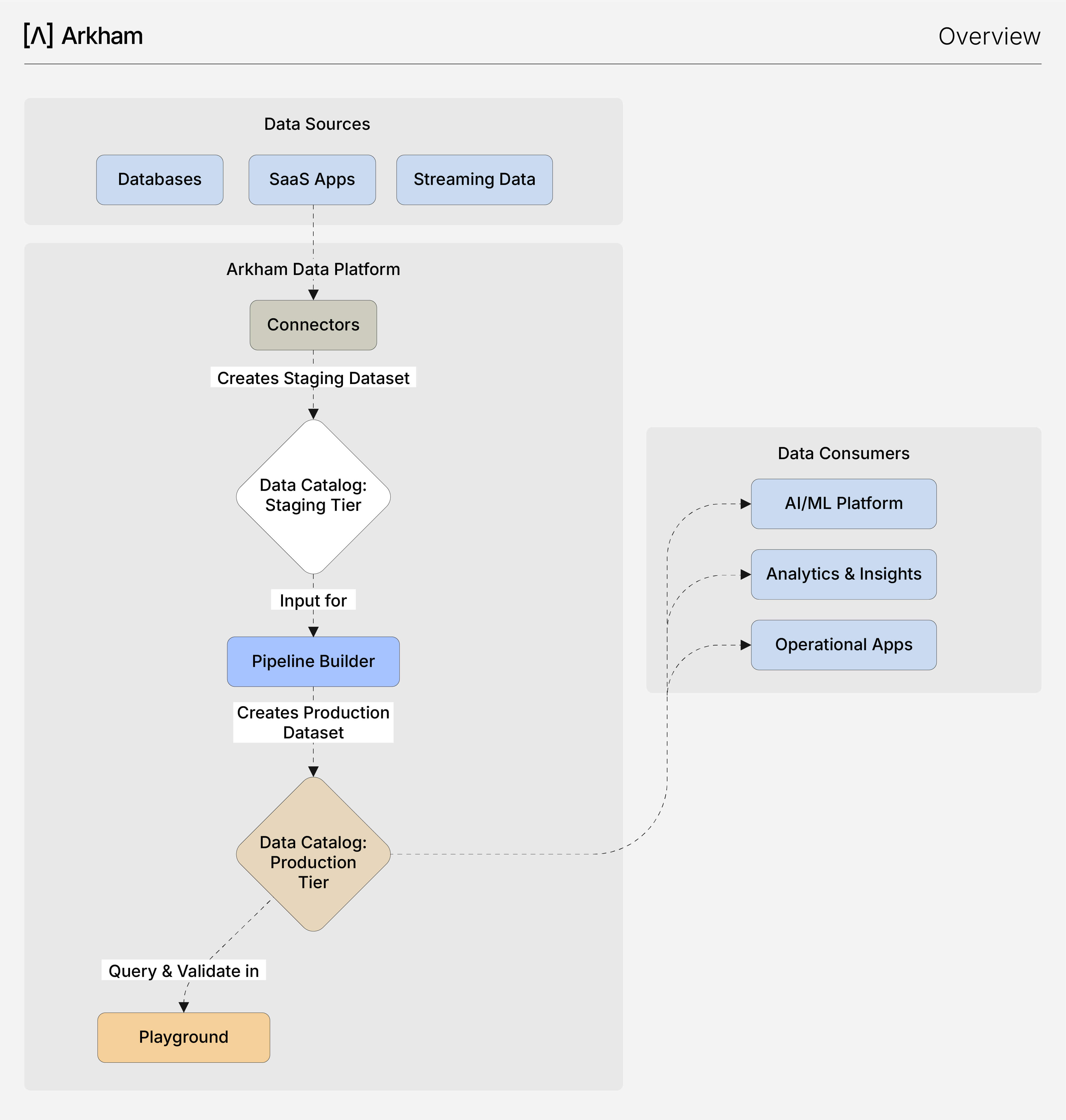
- Ingesta automatizada: Tu viaje comienza en Conectores, donde configuras las conexiones con tus sistemas origen mediante una interfaz sencilla. Arkham se encarga de la ingestión gestionada, depositando de forma confiable tus datos en bruto en un dataset de Staging dentro del Catálogo de Datos. Esto te proporciona una instantánea consultable de tus datos fuente sin necesidad de scripts manuales.
- Transformación visual: Con los datos en el nivel de Staging, utilizas Pipeline Builder para limpiar, unir y agregar la información. Esta herramienta basada en un lienzo visual te permite construir transformaciones complejas de manera intuitiva. A medida que avanzas, cada transformación puede previsualizarse, validarse y guardarse. El resultado final se publica como un dataset de Producción limpio y confiable, automáticamente registrado en el Catálogo de Datos.
- Descubrimiento y exploración instantáneos: El Catálogo de Datos funciona como tu registro central, indexando automáticamente tanto los datasets de Staging como los de Producción. Desde el catálogo puedes visualizar los esquemas, rastrear el linaje y gestionar accesos. Para validaciones rápidas o análisis ad-hoc, puedes acceder directamente a Playground, un entorno SQL integrado para consultar cualquier dataset.
- Consumo y enriquecimiento: Tus datasets de Producción, de alta calidad, se convierten en la base confiable para todas las aplicaciones posteriores. Son consumidos por la Plataforma de IA para entrenar modelos y por herramientas de inteligencia de negocio para análisis. A su vez, la Plataforma de IA genera nuevos datasets valiosos de modelos ML (por ejemplo, predicciones o métricas de desempeño), que se registran nuevamente en el Catálogo de Datos, creando un ciclo virtuoso de enriquecimiento de datos.
Este flujo prescriptivo asegura que tus datos estén siempre gobernados, tus pipelines sean robustos y tus ciclos de desarrollo cortos, permitiéndote construir e iterar con mayor rapidez.
Capacidades relacionadas
La Plataforma de Datos es la base para otras capacidades clave dentro del ecosistema Arkham:
- Plataforma de AI: Consume datasets de producción para entrenar modelos y generar insights.
- Ontología: Mapea objetos y métricas a los datasets confiables curados por la Plataforma de Datos.
- Gobernanza: Proporciona el marco para asegurar y auditar todos los activos creados y gestionados dentro de la Plataforma de Datos.
- TARS: Nuestro copiloto de IA asiste en todos los componentes de la Plataforma de Datos, desde generar SQL hasta explicar la lógica de los pipelines.