

Conectores de Datos: Automatiza la Ingesta de Datos
El primer tramo de cualquier proyecto de datos suele ser el más difícil. Crear y mantener scripts personalizados de ingesta es un cuello de botella que consume muchos recursos, requiere horas de ingeniería y retrasa proyectos críticos. Cuando cambia una API fuente, estos pipelines frágiles fallan, debilitando la confianza en tus datos.
Los Conectores de Arkham están diseñados para resolver este problema. Ofrecemos una biblioteca de integraciones preconstruidas y listas para producción que automatizan la carga de datos desde cualquier sistema fuente directamente en el Lakehouse de Arkham. En lugar de escribir código, tu equipo utiliza una interfaz sencilla para crear sincronizaciones confiables en minutos, no semanas, permitiéndoles enfocarse en generar valor y no en administrar infraestructura.
Cómo Funciona: De la Fuente a la Preparación
Nuestros Conectores de Datos simplifican todo el proceso de ingesta a través de una interfaz de bajo código. Esta arquitectura garantiza que los datos lleguen de forma confiable y puntual a la Capa de Preparación de tu Catálogo de Datos, listos para su transformación.Staging Tier of your Data Catalog reliably and on schedule, ready for transformation.
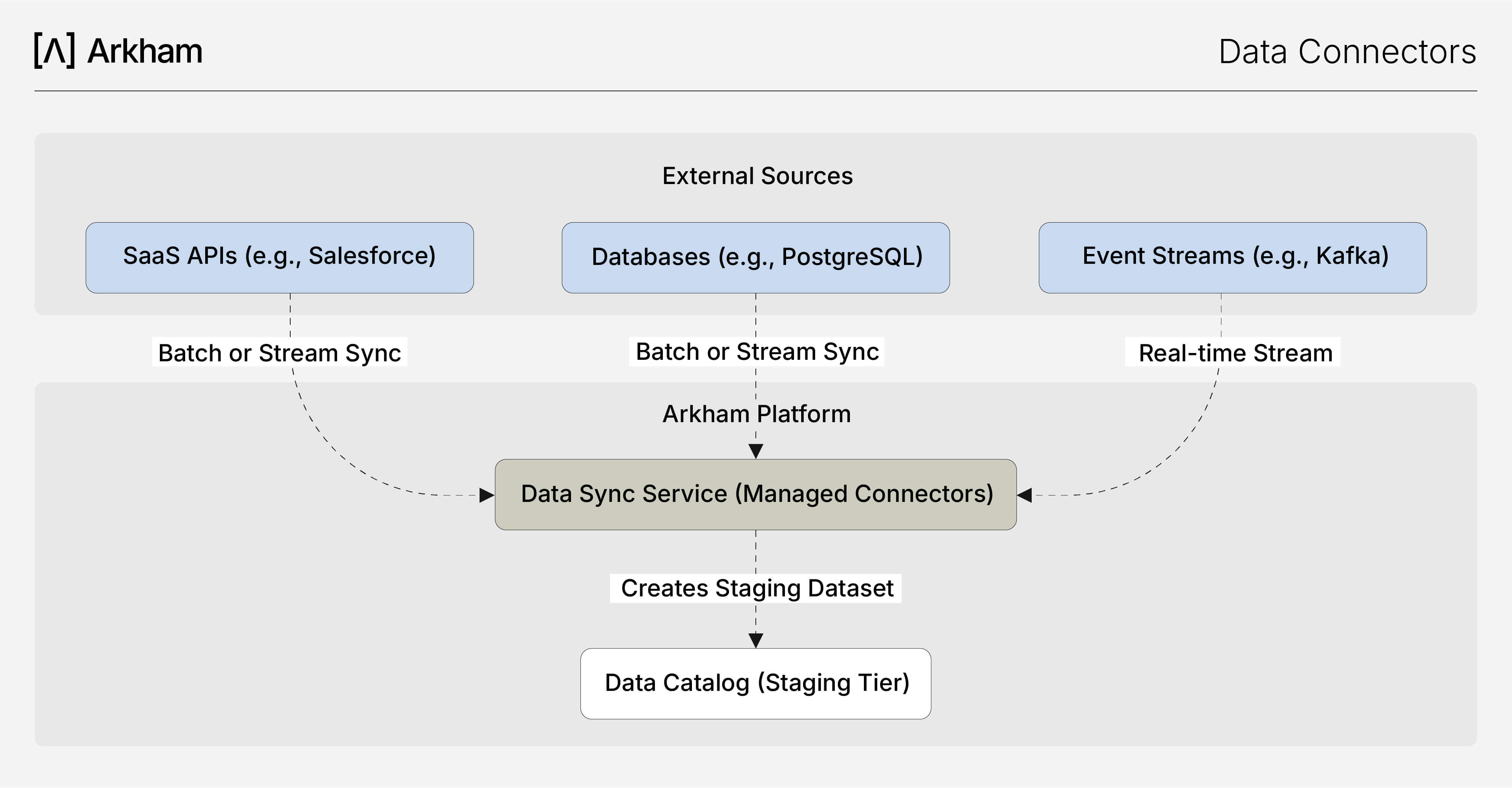
El proceso es sencillo y puede ejecutarse a través de una interfaz de bajo código o acelerarse con TARS.
- Seleccionar un conector: Elige entre una amplia variedad de fuentes disponibles en la interfaz.
- Configura Credenciales: Proporciona las credenciales de acceso de forma segura a través de nuestra bóveda integrada.
- Define el Comportamiento de la Sincronización: Selecciona las tablas, temas u objetos a sincronizar y define el calendario (por ejemplo: por lotes, incremental o en tiempo real).
- Monitorea y Administra: Supervisa los trabajos de sincronización, consulta los registros y gestiona las conexiones desde un panel de control centralizado.
🤖 AI-Assisted Ingestion with TARS
También puede realizar estas acciones conversacionalmente usando TARS. En lugar de navegar por la interfaz de usuario, simplemente puede preguntar:
“Crear un nuevo flujo para extraer pedidos de la tabla fuente PostgreSQL y ejecutarla cada hora”.TARS también puede responder preguntas sobre configuraciones de conectores o verificar el estado de un trabajo de sincronización, lo que reduce el esfuerzo manual.
Principales Beneficios Técnicos
- Desarrollo Acelerado: Pasa de la fuente a los datos en bruto en minutos. Al aprovechar nuestra biblioteca preconstruida, tu equipo puede enfocarse en la transformación de datos y la creación de valor en lugar de construir y mantener scripts de ingesta frágiles.
- Infraestructura Gestionada y Escalable: Arkham administra los conectores, asegurando que siempre estén actualizados con los cambios en las API de las fuentes. El servicio escala automáticamente para manejar terabytes de datos sin intervención manual.
- Gestión Automatizada de Esquemas: Nuestra plataforma detecta automáticamente cambios de esquema en tus datos fuente. Para fuentes en evolución, puedes activar la opción "Ejecutar con sobrescritura de esquema" en tu trabajo de sincronización para propagar estos cambios sin problemas a tu conjunto de datos de preparación, previniendo fallos en los pipelines."Run with schema overwrite" option on your sync job to seamlessly propagate these changes to your Staging Dataset, preventing pipeline failures.
- Control Centralizado y Gobernanza: Administra todas las credenciales de fuente y los horarios de sincronización en un solo lugar. Este enfoque unificado simplifica la seguridad, asegura el cumplimiento y proporciona visibilidad clara de la trazabilidad de los datos desde el inicio.
- Diseñado para la Actualidad: Con soporte nativo para carga incremental y streaming en tiempo real, puedes impulsar análisis sensibles al tiempo y flujos operativos con los datos más actualizados posibles.
Fuentes Soportadas
Nuestra biblioteca está en continua expansión. Las categorías clave incluyen:
- Bases de datos: PostgreSQL, MySQL, MongoDB
- Aplicaciones SaaS: Salesforce, SAP, Workday
- Almacenes de datos: BigQuery, Redshift, Copo de nieve
- Transsecuencias de eventos: Apache Kafka, AWS Kinesis
- Almacenamiento de archivos: Amazon S3, Azure Blob Storage, Google Cloud Storage
Capacidades Relacionadas
- Visión General de la Plataforma de Datos: Ve cómo los Conectores encajan en el flujo de datos de extremo a extremo.
- Catálogo de datos: El registro central donde tus conjuntos de datos de preparación recién creados son descubiertos y gestionados automáticamente.
- Pipeline Builder: El siguiente paso lógico para limpiar, unir y transformar los datos en bruto que has ingerido.
- TARS: Tu copiloto de IA para acelerar la configuración y gestión de tus sincronizaciones de datos.